- The data: 11 sites, 24 months, one survivor
- Seven archetypes of directory outcomes
- Lesson 1 — Curated rankings slow the bleed; data dumps don't
- Lesson 2 — Reddit owns lifestyle queries; go there
- Lesson 3 — The funnel top is the moat (NerdWallet vs. Zillow)
- Lesson 4 — First-party data is the only durable moat
- Lesson 5 — GEO/AEO matters, but isn't enough (the Wikipedia paradox)
- Lesson 6 — The distribution-layer pivot (Yelp's decoupling)
- The decision matrix for directory operators
- Case study: tapwaterdata.com — running the audit on my own site
- What this analysis does not claim
- Methodology and appendix
- The data: 11 sites, 24 months, one survivor
- Seven archetypes of directory outcomes
- Lesson 1 — Curated rankings slow the bleed; data dumps don't
- Lesson 2 — Reddit owns lifestyle queries; go there
- Lesson 3 — The funnel top is the moat (NerdWallet vs. Zillow)
- Lesson 4 — First-party data is the only durable moat
- Lesson 5 — GEO/AEO matters, but isn't enough (the Wikipedia paradox)
- Lesson 6 — The distribution-layer pivot (Yelp's decoupling)
- The decision matrix for directory operators
- Case study: tapwaterdata.com — running the audit on my own site
- What this analysis does not claim
- Methodology and appendix
How Directory Sites Are Surviving the AI Era: 11 Sites, 24 Months of Ahrefs Data

Of 11 directory sites I audited against the Ahrefs API in April 2026, only one is still growing organically. Two-thirds have lost between 21% and 98% of US organic traffic in the last 24 months. And one of the sites in this dataset is mine.
If you run a directory — a database of cities, schools, doctors, products, restaurants, anything — you already feel this. The traffic charts on the operator side of the curtain look like the chart below. What's not obvious from a single dashboard is that the survivors are not random. There are exactly three patterns that are working in 2026, and exactly one pattern that is dying. This article is the data behind that claim, the six lessons I extracted from it, and a decision matrix you can run on your own directory in the next thirty minutes.
I'll be transparent up front: I'm an operator, not an analyst. One of the directory sites I run — TapWaterData, a US municipal water-quality directory — is structurally identical to bestplaces.net, the worst-performing site in this dataset (down 86.6%). I had every reason to want this analysis to come back optimistic. It didn't. So I'm publishing the raw numbers and what I'm doing about it on my own site, in the hope that other directory builders save themselves some time. (For more on how I'm monetizing that data, see my earlier writeup: How I built an AI sales agent for my directory in one day.)
+17.4%
Only growing site (Zillow)
−64.6%
Worst-hit lead-gen (NerdWallet)
−97.6%
Closest to zero (city-data.com)
11 / 24 / 1
Sites / months / survivor
The chart at the top of this page sums it up: only Zillow is positive, and the rest fall on a steep curve from −9.6% to −97.6%. Here is the upfront data table. Everything else in the article is built on it.
The data: 11 sites, 24 months, one survivor
| Site | 2024-04 traffic | 2026-03 traffic | Δ 24mo | 2026-03 traffic value | Δ value 24mo | Model |
|---|---|---|---|---|---|---|
| zillow.com | 28.9M | 33.9M | +17.4% | $968M | +50.9% | Lead-gen for agents + mortgage |
| yelp.com | 89.8M | 81.2M | −9.6% | $9.16B | +4.0% | Local ads + data licensing |
| allrecipes.com | 36.8M | 29.0M | −21.3% | $180M | −26.8% | Display ads + brand |
| niche.com | 2.7M | 1.99M | −26.5% | $187M | −38.0% | Lead-gen for schools |
| tripadvisor.com | 68.8M | 48.0M | −30.2% | $2.05B | −34.1% | Hotel meta + Viator |
| healthline.com | 52.1M | 25.3M | −51.5% | $724M | −59.5% | Display ads (medical) |
| chegg.com | 1.34M | 610K | −54.6% | $16.5M | −48.4% | Subscription study help |
| webmd.com | 57.2M | 21.7M | −62.1% | $807M | −71.6% | Display ads (medical) |
| nerdwallet.com | 20.7M | 7.34M | −64.6% | $2.52B | −61.7% | Lead-gen on credit cards |
| bestplaces.net | 413K | 55K | −86.6% | $1.09M | −84.6% | Display ads + paywall |
| city-data.com | 1.09M | 26K | −97.6% | $626K | −99.4% | Display ads + abandoned forum |
Sorted by 24-month traffic delta, best to worst. All values: US organic only, Ahrefs Site Explorer, mode=subdomains, April 2024 vs. March 2026.
Why these 11 sites, why now
I picked these specifically because they cover the full range of directory archetypes — pure data dumps (city-data, bestplaces), curated rankings with reviews (niche, allrecipes), classic lead-gen (zillow, nerdwallet), local-services marketplace (yelp, tripadvisor), and information-heavy databases (healthline, webmd, chegg). The window — April 2024 to March 2026 — straddles the rollout of Google's AI Overviews (May 2024) and three core updates (August 2024, November 2024, December 2025). If a directory pattern was going to be tested by the AI era, it was tested in this window.
I'm intentionally not using Similarweb totals or visibility scores. Those numbers move for unrelated reasons (paid traffic, app traffic, brand searches) and they have produced some very confused takes in the past nine months. Ahrefs estimates US organic search traffic specifically, which is what we actually care about. They are estimates, not GA-confirmed sessions, and I treat them as reliable for relative comparison across domains and months — not as ground truth for any single number. The full methodology is in the appendix at the bottom; the raw JSON and CSVs are linked there too.
What I had to correct during validation
Five things I had wrong before I pulled the data
- Niche.com is not recovering. I had read multiple posts claiming Niche was up 170% in the AI era. That number was Similarweb total visits — a different metric on a different basis. Ahrefs US organic shows Niche flat at 2.0–2.2M across 2025–2026. Holding the floor, not climbing.
- AllRecipes is also collapsing. Brand + scale + 30M user reviews and they're still down 21% YoY. Listicles slow the bleed; they don't reverse it.
- NerdWallet is down 64.6%, not 73%. The earlier number I had circulated was peak-to-trough, not anchored to a stable baseline. NerdWallet bottomed at 6.32M in January 2026 and has clawed back to 7.34M — a +16% recovery from the trough but still way off the April 2024 baseline.
- WebMD is down 62.1%, not 43%. The earlier figure was a visibility score, not traffic.
- Yelp's organic is down, but Yelp itself is growing. Yelp's US organic is down 9.6%. But Yelp's estimated traffic value is up 4.0%, and per Yelp's IR, net revenue hit a record in 2025 with 2026 guidance of $1.46B–$1.48B. The decoupling is the most interesting thing in this dataset.
Publishing the corrections is part of the EEAT story. I had to throw out three of my own working assumptions to write this. If your gut says directory X is a survivor, pull the Ahrefs data on it before you bet your roadmap on it.
Seven archetypes of directory outcomes
Looking at the trajectories, the same 11 sites split cleanly into seven categories, each with a different underlying pattern. The categorization is what powers the rest of this article.
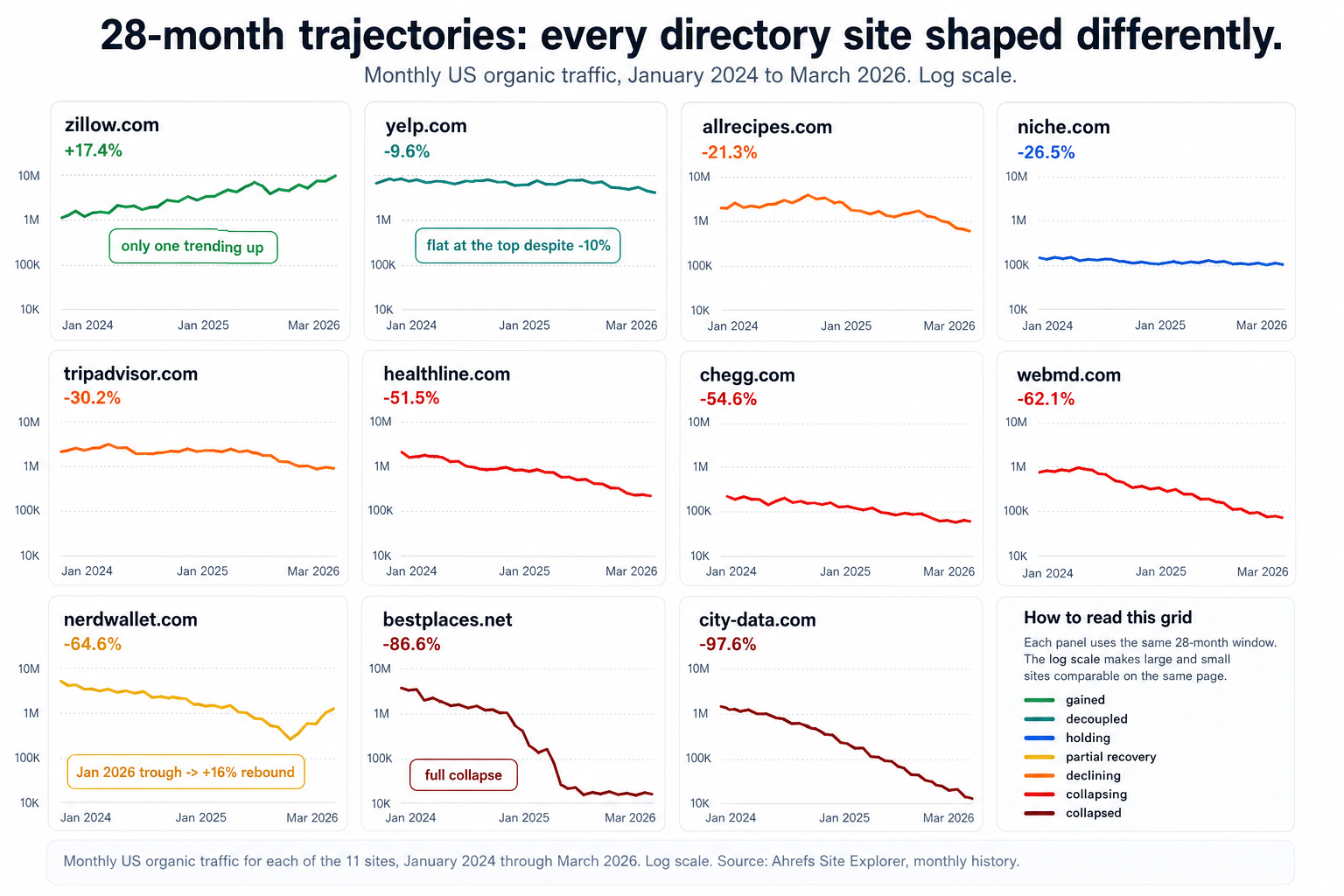 Monthly US organic traffic for each of the 11 sites, January 2024 through March 2026 (log scale). Source: Ahrefs Site Explorer, monthly history.
Monthly US organic traffic for each of the 11 sites, January 2024 through March 2026 (log scale). Source: Ahrefs Site Explorer, monthly history.
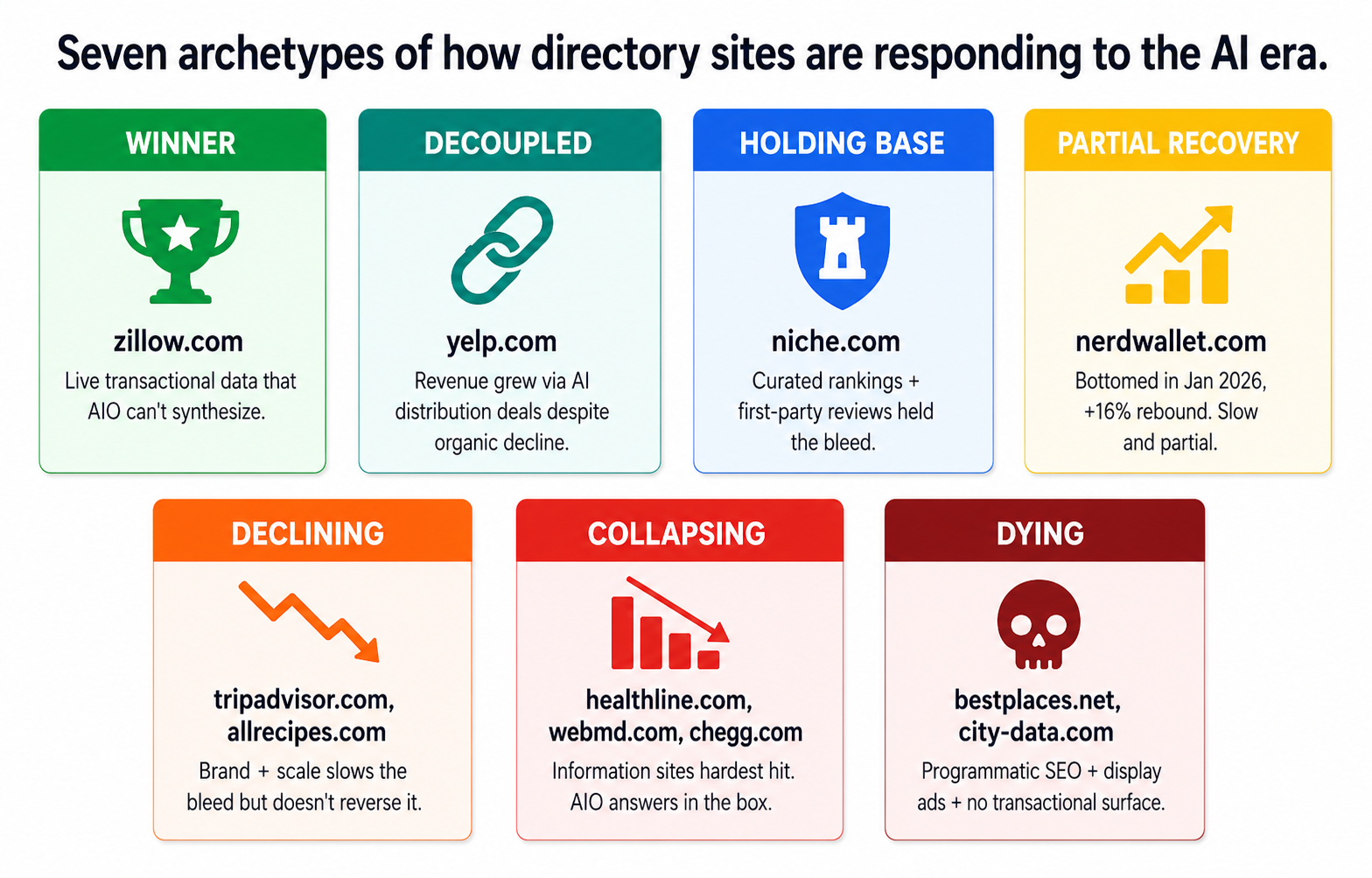 Seven archetypes that the 11 sites in this dataset cluster into. The patterns repeat across verticals.
Seven archetypes that the 11 sites in this dataset cluster into. The patterns repeat across verticals.
Now the six lessons.
Lesson 1 — Curated rankings slow the bleed; data dumps don't
The takeaway: programmatic pages that answer "best of" questions still survive. Programmatic pages that dump public data at the user are gone.
The cleanest pair in the dataset is Niche.com vs. bestplaces.net.
- Niche.com has held its US organic essentially flat at 2.0–2.2M monthly across 2025 and into 2026. Down 26.5% from baseline, but not collapsing.
- Bestplaces.net has lost 86.6% of US organic over the same window — from 413K monthly to 55K.
These are both city/place directories. They both pull from public data sources. They look similar from the outside. So what's different?
The dominant URL pattern. Niche's /colleges/search/* cluster — its programmatic listicle pattern — is doing roughly 2,138 monthly visits per page. Bestplaces.net's data-dump pages (one per city, dumping every available stat into a long table) do roughly 40 monthly visits per page.
That's a 40–50× gap on the same architectural decision.
The mechanism is straightforward. Niche's pages answer a question that requires opinion ("which colleges in [state] are best for X"). Bestplaces' pages answer a question that AI Overviews now handles in two sentences ("what is the population of [city]"). When a user types the bestplaces query into Google in 2026, the AIO surface gives them the answer above the fold and the click never happens. When a user types Niche's query, the AIO surface still surfaces a list of options — and Niche's curated ranking, with reviews, is one of the canonical sources it pulls from.
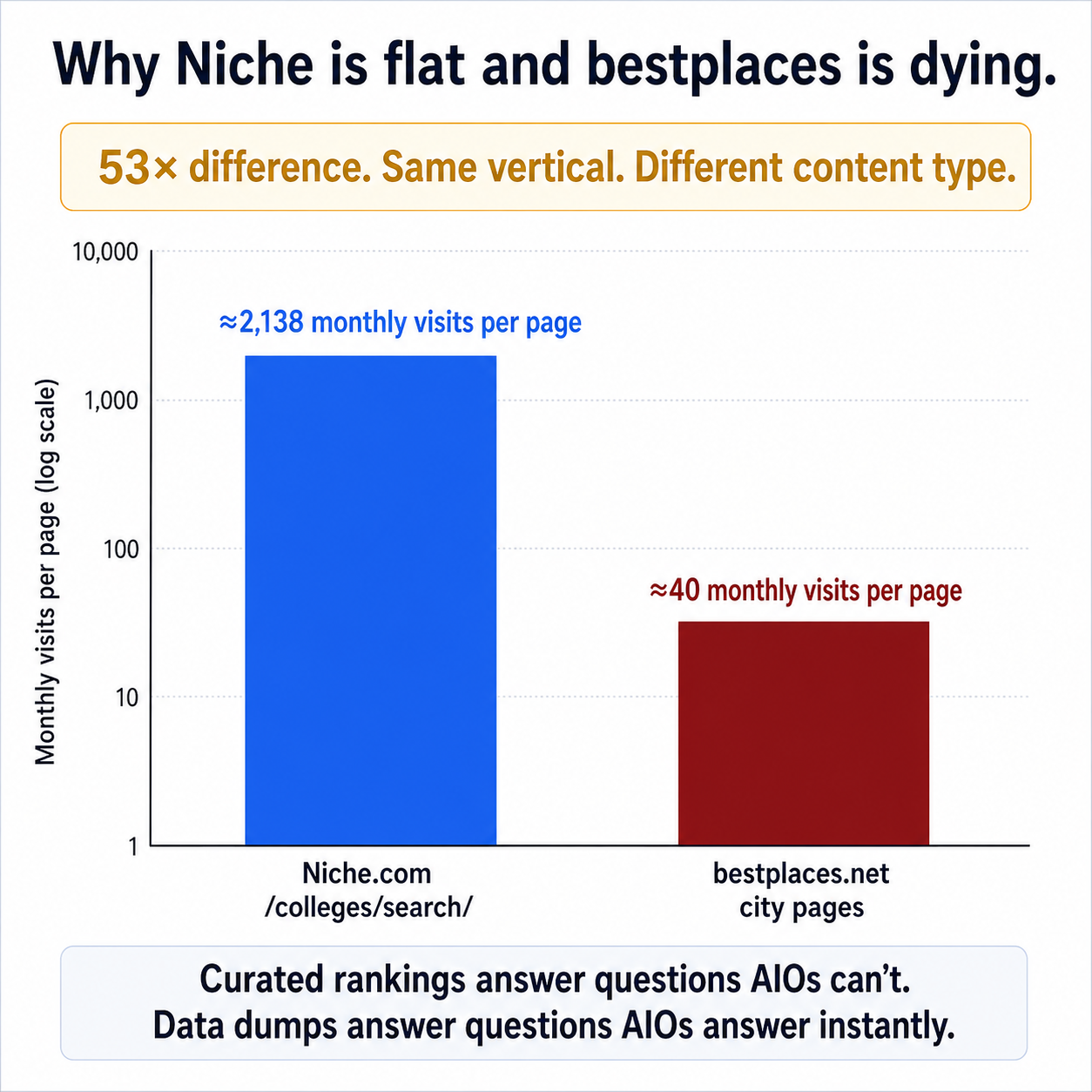 Niche's curated college rankings yield roughly 53× the per-page traffic that bestplaces' data-dump city pages do — even though both are programmatic at scale.
Niche's curated college rankings yield roughly 53× the per-page traffic that bestplaces' data-dump city pages do — even though both are programmatic at scale.
The honest caveat
Listicles are not a magic shield. Look at AllRecipes in the headline table: scale (29M monthly US organic), brand recognition (top-of-mind), and 30M+ user reviews — and they are still down 21.3% YoY and roughly 36% from their April 2025 peak. Curated rankings slow the bleed. They don't reverse it on their own.
The anti-pattern: scaled AI listicles
The cautionary tale here is the National Today case Glenn Gabe wrote about in 2025. National Today scaled to roughly 850,000 AI-generated pages in 2024–2025. Google issued them a manual action and, just as importantly, they lost their AIO citations at the same time. The penalty wasn't just an organic loss; it was an exit from the AI surface entirely. If you let an LLM write your listicles end-to-end, you are setting yourself up for the same outcome.
How to migrate a data-dump directory
If you run a data-dump directory today, here's the migration path:
- Find the question that requires opinion in your vertical. "Best [thing] for [persona] in [year]" or "[brand A] vs. [brand B]" or "Best [thing] in [city]." That's the URL pattern that survives.
- Pick a methodology. Even a sloppy methodology is better than none. Publish a
/methodologypage that explains how the ranking is generated, what's weighted, and how often it refreshes. This is what separates a survivable listicle from spam. - Bake the year into the URL.
/best/[thing]/2026. Plan a 301 redirect strategy now (/2026→/2027next year, with the old URL becoming a "see latest" page). Annual refresh is a survival signal. - Add
ItemList+ListItemJSON-LD withAggregateRatingandProductschema (withOffer.sponsoredfor affiliate links). This is the structured data the AIO actually reads. - Ship one template family, measure for two weeks, then ship the next. Don't mass-generate 200 templates. Glenn Gabe's case shows what happens to operators who do.
Lesson 2 — Reddit owns lifestyle queries; go there
The takeaway: for personal-experience queries, AI Overviews cite Reddit threads over directories. Treat Reddit as a second discovery surface, not as competition.
Look at any AI Overview response to a "is X safe" or "is X worth it" or "what should I do about X" query in 2026. Then look at the cited sources. There's almost always a Reddit thread in the citation list.
According to Digital Bloom's 2025 AIO citation analysis, Reddit citations in AI Overviews grew 450% during the rollout window. Wikipedia is the most-cited source overall (more on that in Lesson 5), but Reddit is the fastest-growing source for everything that smells like a personal-experience question.
For directory operators, this is both a threat and a distribution channel.
It's a threat because for many queries — "is the water in [city] safe?", "should I get a water softener?", "is [brand] worth the money?" — the LLM will cite Reddit and not your directory. Your structured data and JSON-LD don't matter if the model decides personal-experience answers are more trustworthy than database answers.
It's a distribution channel because the same Reddit posts get clicks, build referral traffic, and accumulate AIO citations to your site if you participate well. Subreddits that overlap with your vertical can become a second discovery surface that doesn't depend on the SERP.
The 5-subreddit operating template
For my water-quality vertical, here are the 5 subreddits where the LLMs source answers about tap water:
- r/wellwater — well-water testing, pump issues, contamination
- r/Plumbing — installation, equipment, water-flow issues
- r/HomeImprovement — broad household water-quality questions
- r/Flint — Flint-specific water-quality discussion (high-LLM-citation source)
- r/Jackson_MS — Jackson MS-specific (similar)
The operating cadence: 2–3 helpful posts per week per subreddit, on the operator account, no link drops, citing your data only when directly relevant. This is a 6-month strategy, not a 6-week one. Build authority on the platform, then let the citations accumulate.
For your vertical, the equivalent template is: pick the 5 subreddits where someone with your customer's question is most likely to land. If it's not obvious, search the subreddit names with your top 10 search queries on Google and see which subreddit threads rank.
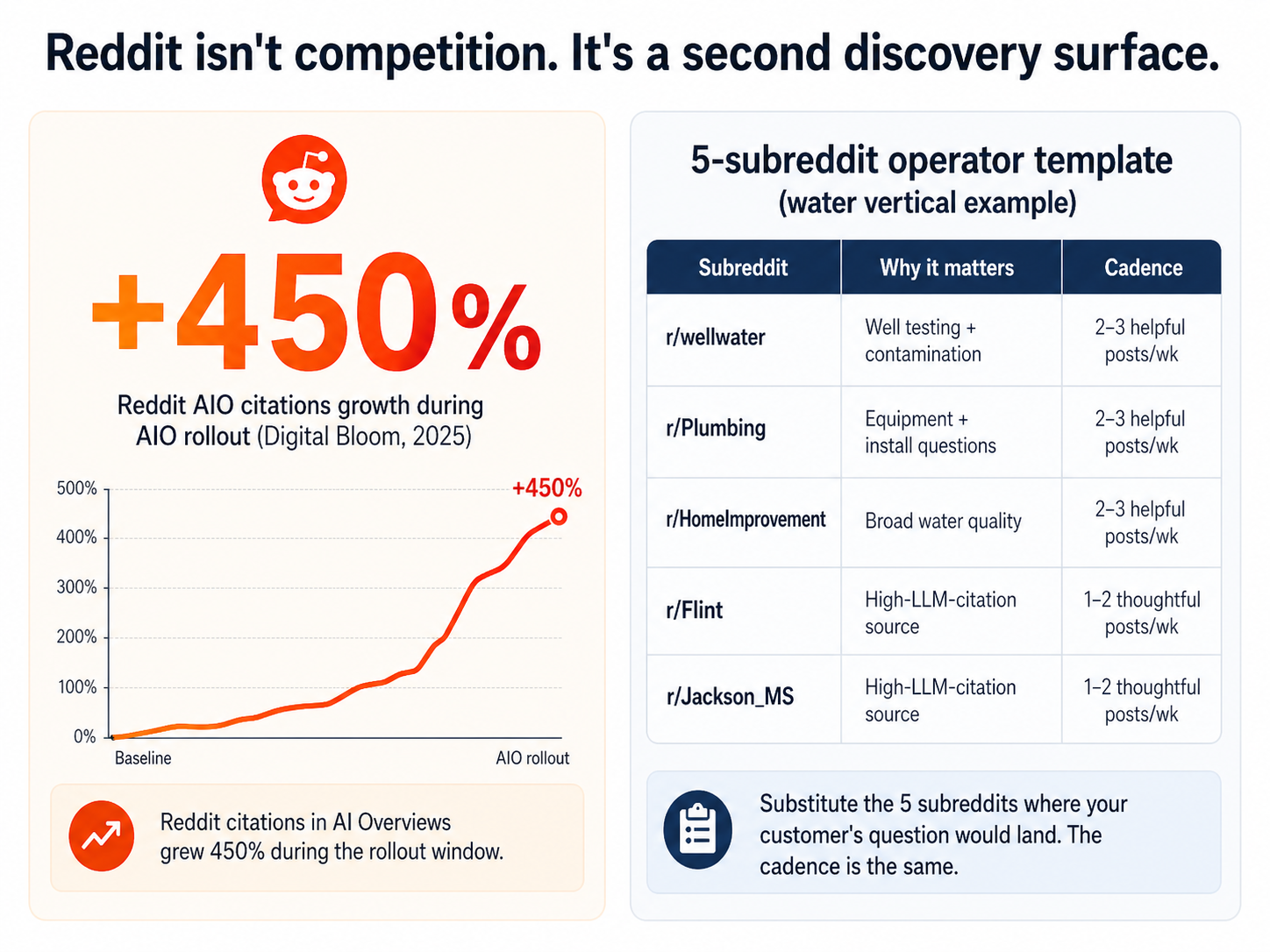 Reddit citations in AI Overviews grew roughly 450% during the rollout window (Digital Bloom, 2025). The operating template generalizes to any directory vertical.
Reddit citations in AI Overviews grew roughly 450% during the rollout window (Digital Bloom, 2025). The operating template generalizes to any directory vertical.
Lesson 3 — The funnel top is the moat (NerdWallet vs. Zillow)
The takeaway: same business model can grow or collapse depending on whether the funnel-top query requires live, transactional data. This is the most important pattern in the dataset.
Look at NerdWallet and Zillow side by side:
| Metric | NerdWallet | Zillow |
|---|---|---|
| 2024-04 US organic | 20.7M | 28.9M |
| 2026-03 US organic | 7.34M | 33.9M |
| Δ 24 months | −64.6% | +17.4% |
| 2024-04 traffic value | $6.57B | $642M |
| 2026-03 traffic value | $2.52B | $968M |
| Δ value 24 months | −61.7% | +50.9% |
| Funnel top | "best credit card for X" | "homes for sale in [city]" |
| Monetization | Lead-gen on credit cards / loans | Lead-gen for agents + mortgage |
Same business model — both are lead-gen marketplaces with high-CPC paid placements at the bottom of the funnel. Same vintage. Same scale of operation. Opposite outcomes.
The difference is the funnel top.
Zillow's top-of-funnel is "homes for sale in [city]" or a specific listing. That query requires live MLS data the AI Overview cannot synthesize — the listings change hourly, the prices change daily, and any synthetic answer is wrong by the time you read it. Google's AIO can't fake a real-estate listing for [Address]. So the user clicks through to Zillow, and Zillow gets paid downstream.
NerdWallet's top-of-funnel is "best credit card for [purpose]". That query is exactly what the AI Overview is built to answer. The model doesn't need to fetch live data; the comparison criteria are stable; the answer can be generated in the box. The user gets a perfectly useful answer without clicking, and NerdWallet doesn't get paid.
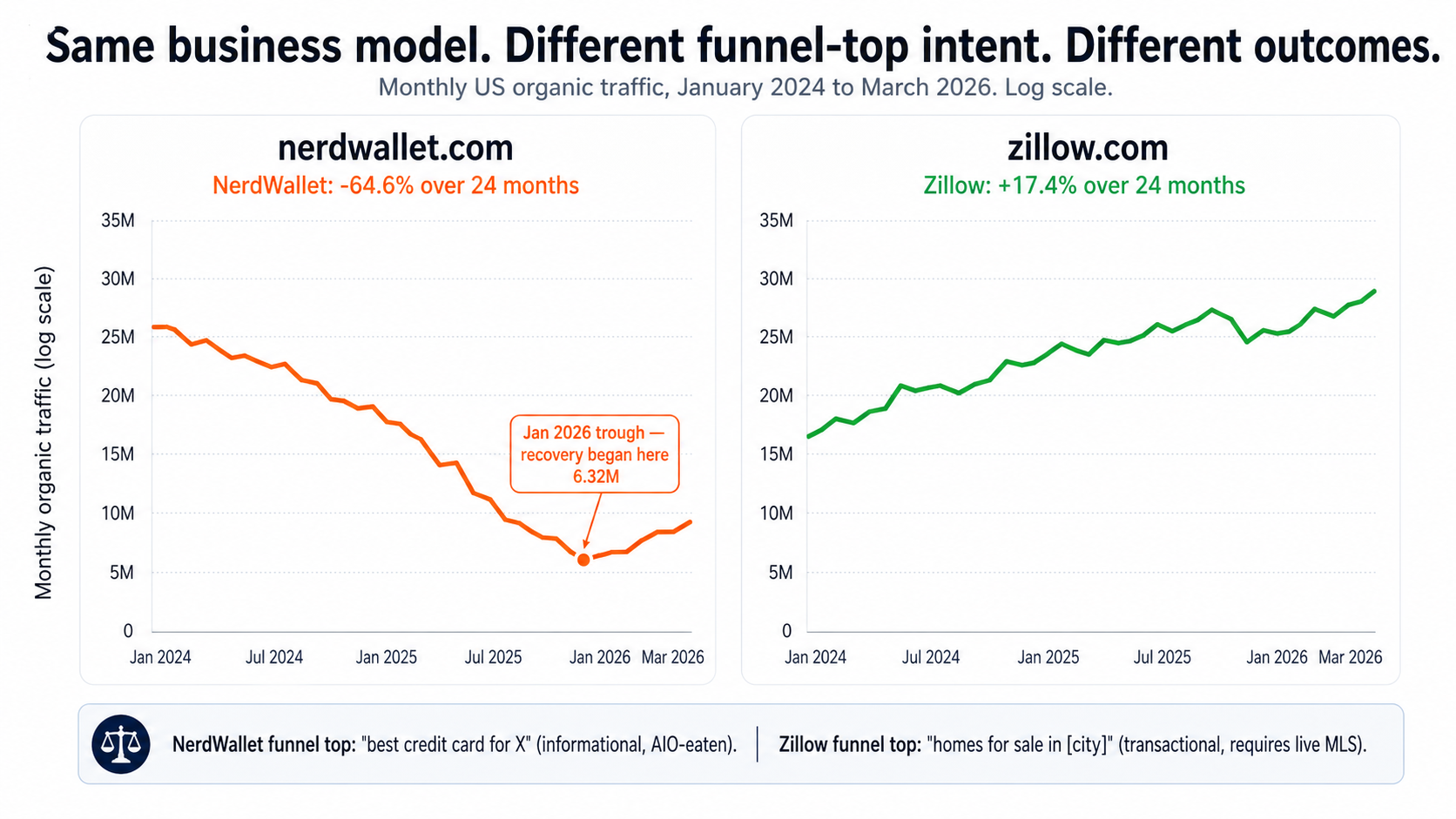 NerdWallet and Zillow run essentially the same business — high-CPC lead-gen marketplaces. The only thing that's different is what query brings the user in.
NerdWallet and Zillow run essentially the same business — high-CPC lead-gen marketplaces. The only thing that's different is what query brings the user in.
The pattern that explains the divergence is a 2x2 you can map any URL pattern onto.
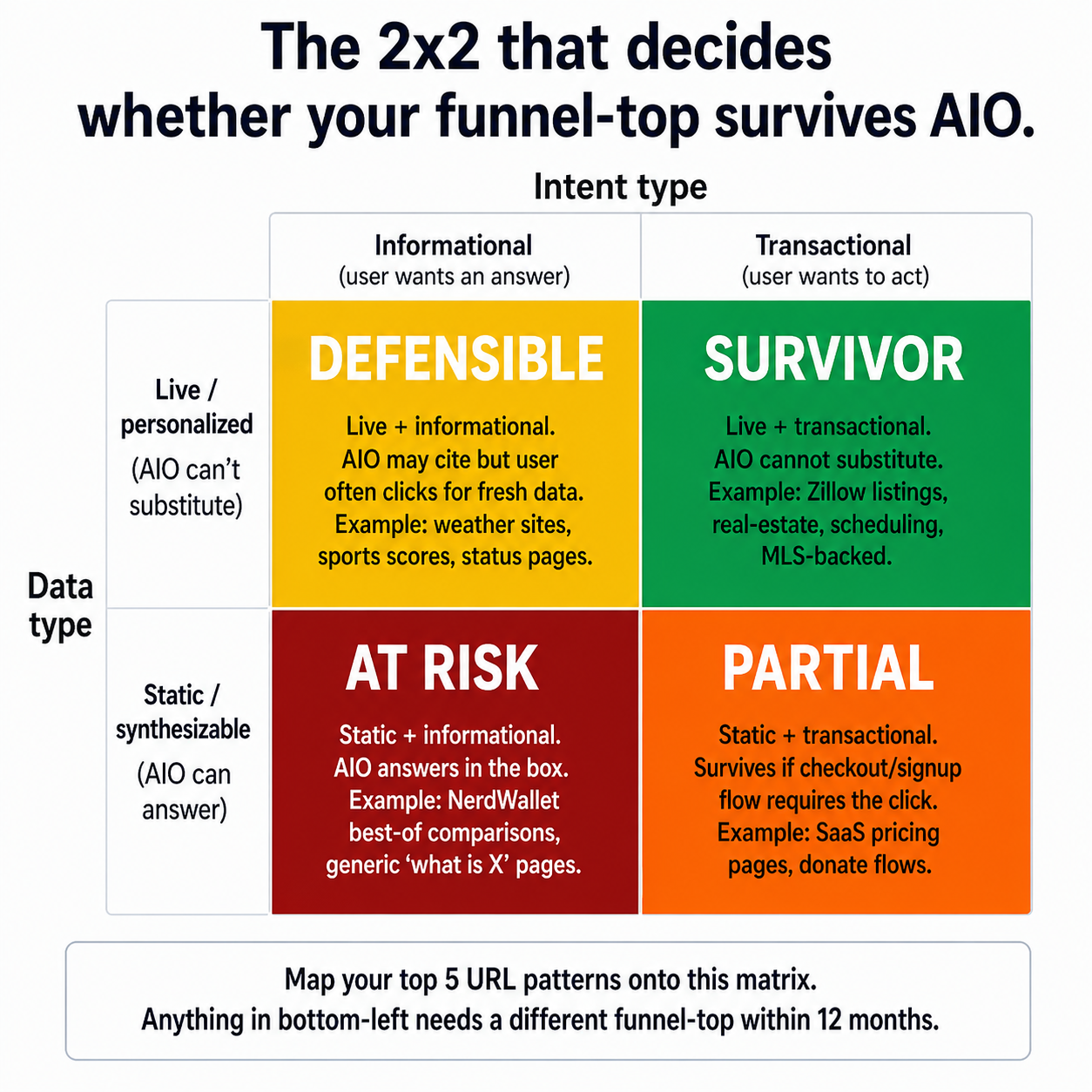 The 2x2 that explains why Zillow grew and NerdWallet collapsed. Map your top 5 URL patterns onto it — anything in the bottom-left quadrant needs a different funnel top within 12 months.
The 2x2 that explains why Zillow grew and NerdWallet collapsed. Map your top 5 URL patterns onto it — anything in the bottom-left quadrant needs a different funnel top within 12 months.
Recovery is possible — slow and partial
Here's the encouraging part of the NerdWallet trajectory:
| Month | US organic | MoM Δ |
|---|---|---|
| 2025-10 | 9.44M | — |
| 2026-01 | 6.32M (TROUGH) | bottom |
| 2026-02 | 7.17M | +13.3% |
| 2026-03 | 7.34M | +2.4% |
NerdWallet rebounded 16% from its January 2026 trough in two months. They're still down 64.6% from baseline, but they have stopped falling and started climbing. Lead-gen sites can recover. But notice: even after two months of recovery, they're still at a third of their April 2024 traffic. This is what "partial recovery" looks like in 2026.
The 4-question funnel-top audit
Here's the audit I run on every URL pattern in my own directory:
- Does answering this query require live data my user can't get from anywhere else? (Zillow yes; NerdWallet no.) If yes, AIO can't substitute — survivor.
- Is the user committed to taking an action after getting the answer? ("Apply for X" yes; "what is X" no.) If yes, the click is structurally necessary.
- Is the answer different per user? (Personalized loan rate yes; "best card overall" no.) If yes, AIO has to send the user to you to get the personalized version.
- Does my downstream monetization require trust signals only my site can provide? (Verified reviews, claimed listings, audit trails — yes; generic affiliate links — no.) If yes, the brand is part of the moat.
If your top URL patterns answer "no" to all four, you are NerdWallet pre-trough. You can still recover via product/funnel restructuring (which is what NerdWallet did), but the recovery will be slow and partial.
Per-vertical lead-gen economics
For context on where the dollars are: a water-testing referral pays roughly $20–60. A water-softener install lead pays $50–150 to a local installer. A reverse-osmosis install lead pays $40–120. A PFAS class-action signed-retainer lead pays $200–$4,000 (it's a wide range based on case strength). The ceiling on what a directory builder can earn per click is set by the lead value at the bottom of the funnel — not by ad RPMs.
If your current monetization is display ads at $5–15 RPM and a competitor in your vertical can get $200 per signed lead, the math says the competitor wins on the same traffic.
Lesson 4 — First-party data is the only durable moat
The takeaway: public data is no longer a differentiator. User-contributed data is the only thing AI can't synthesize.
Here's a pattern I missed for too long. Look at the survivors in this dataset:
- Niche.com — millions of parent and student reviews
- AllRecipes — 30M+ user reviews
- Yelp — claimed-business profiles, hundreds of millions of reviews
- Zillow — agent profiles, listing histories, owned data on listing changes
What do they have in common? The data on the page is not derivable from public sources. It was contributed by users who created it specifically for that platform.
Now look at the dying sites:
- Bestplaces.net — Census + BLS + Climate data, all public
- City-data.com — Census + various public datasets (we wrote up its model in a separate case study)
- NerdWallet (mostly) — credit card terms are public, lender APRs are derivable
The pattern is brutal: public data is no longer differentiated. An AI model can synthesize from primary sources (Census Bureau, EPA SDWIS, NCES, BLS) faster and more accurately than a directory can crawl, normalize, and republish them. If your value-add was "we organized the public data nicely", that value is gone in 2026. The model organizes the data nicely on demand.
User-submitted data, on the other hand, is something the model cannot synthesize. It exists only because your platform exists. That is the moat.
 Three tiers of data moat. The deeper the tier, the harder for AI to substitute.
Three tiers of data moat. The deeper the tier, the harder for AI to substitute.
The 3-step migration path
If you currently rely on public data, here is the practical sequence to climb the data-moat tiers:
Step 1 — Capture the easiest user signal first. A simple Tally form on your top 10 pages: "Have you experienced [the thing your directory is about]? Share a 2-line note." Optional email opt-in. This is a 30-day experiment with a low bar — 30 valid submissions across 10 pages is enough to validate the surface.
Step 2 — Real submission with manual review. A /submit page with a real form. Approved submissions published as their own URLs (/report/[id] or similar) with structured data, geocoded to a coarse granularity (zip, never street), and aggregated on the relevant directory pages ("23 reports submitted in this zip"). 30 minutes per week of manual review. 100 published reports + 5 organic backlinks in 60 days is the validation gate.
Step 3 — Verified submissions with OCR and trust badges. Once you have flow, add a verification layer (PDF parsing, vision API, badge for verified-source contributions). This is what turns a review platform into a defensible data moat. Aggregate across 30-day windows for "X home tests submitted in [city] this month" rollups — these become natural backlink magnets for local news and trade press.
The privacy guardrails are non-negotiable from day one: opt-in only, display granularity zip + utility (never street), explicit "no third-party sale" statement on the submit page. The trust wall the data-collection sites that survived built (think EWG) is the trust wall you need.
Lesson 5 — GEO/AEO matters, but isn't enough (the Wikipedia paradox)
The takeaway: being cited by AI Overviews is not the same as being paid. Wikipedia is the #1 cited source — and lost 8% of pageviews anyway.
Walk into any GEO/AEO conference talk in 2026 and you'll be told that getting cited by AI Overviews is the new SEO. It's not wrong. But the numbers underneath it are uncomfortable.
According to Digital Bloom's 2025 citation analysis, Wikipedia is the #1 most-cited source in AI Overviews — roughly 1.13 million citations during the analysis window. By any "AI citation surface" definition, Wikipedia won.
In the same window, TechCrunch reported in October 2025 that Wikipedia pageviews dropped roughly 8%.
The lesson: citation surface is not revenue surface. Being cited 1.13 million times in AI Overviews is a strong signal of authority, but it doesn't, by itself, generate clicks, donations, ad revenue, or any other monetizable event. The user got their answer in the AIO box. The citation flatters Wikipedia's reputation. It doesn't fund the servers.
If you treat GEO/AEO as your only strategy, you can become the most-cited source in your vertical and still see your business decline. The citation matters, but only as a funnel input — the conversion happens elsewhere.
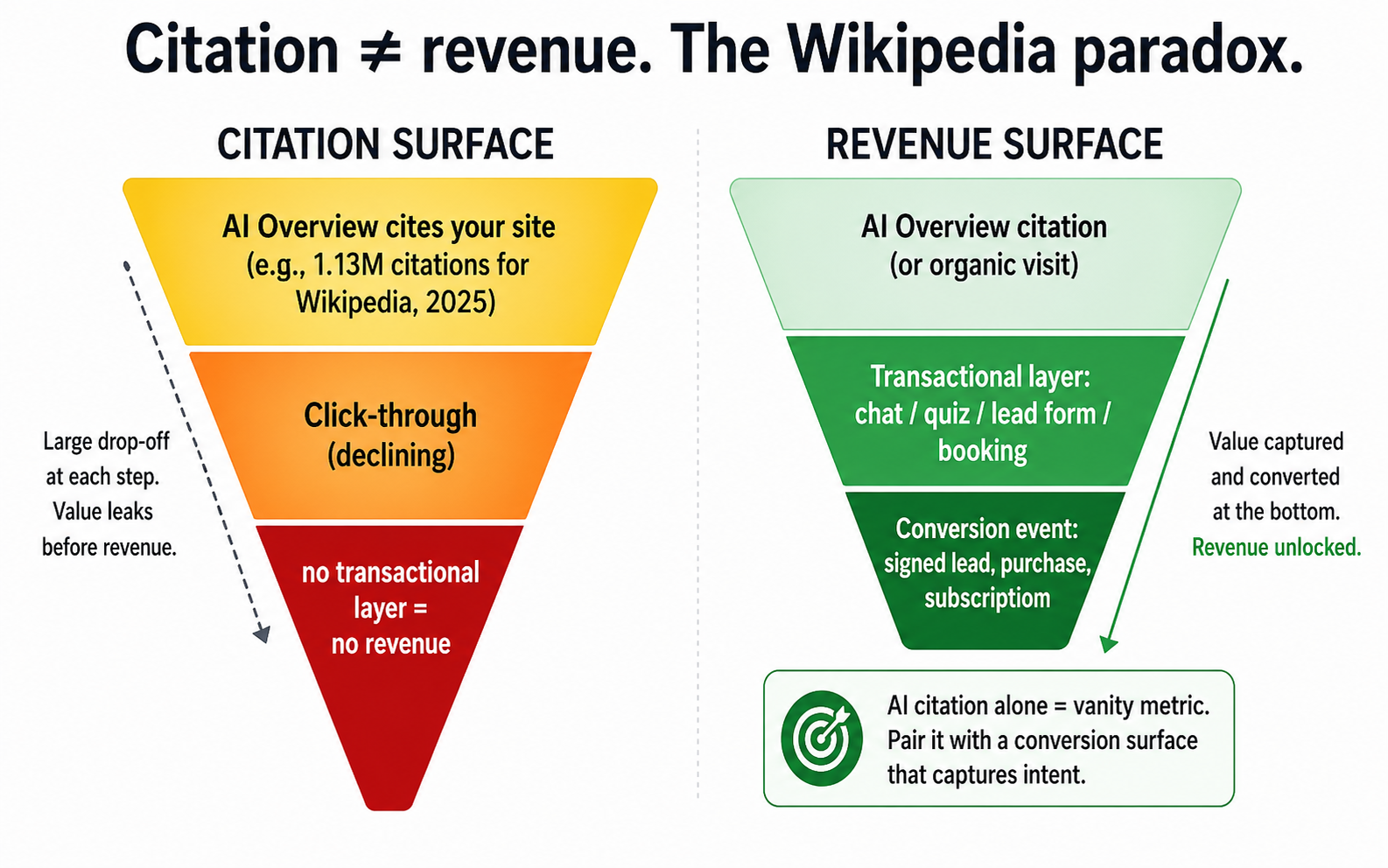 Wikipedia is the #1 most-cited source in AI Overviews and still lost roughly 8% of pageviews (TechCrunch, Oct 2025). Citation surface is the start of the funnel, not the end.
Wikipedia is the #1 most-cited source in AI Overviews and still lost roughly 8% of pageviews (TechCrunch, Oct 2025). Citation surface is the start of the funnel, not the end.
Pair AEO with a transactional layer
Concretely, on every page that's optimized for AIO citation, you want one of:
- A chat or assistant on the page that the user can ask follow-up questions ("OK, you cited this study, but what should I do?"). The chat is the conversion surface.
- A quiz or planner ("answer 5 questions, get a personalized recommendation"). The recommendation is monetized via lead-gen at the bottom.
- A lead form with clear value ("get a free [thing] for your situation"). The form is the conversion event.
- A booking or scheduling widget if your vertical has services. The booking captures intent the AIO summary couldn't fulfill.
If a page that's getting cited has none of these — no way for the user to do anything beyond reading and leaving — the citation is an authority signal that doesn't pay anyone. Build the conversion surface, then optimize for citations.
Lesson 6 — The distribution-layer pivot (Yelp's decoupling)
The takeaway: the highest-leverage move for a directory in 2026 isn't fixing search — it's becoming a data supplier to the AI products that replaced search.
This is the one that changes the strategic horizon for directory operators. Yelp's organic traffic is down 9.6%. Its estimated traffic value held flat at +4%. And per Yelp's investor relations, its actual net revenue hit a record in 2025, with 2026 guidance of $1.46B–$1.48B. The three lines diverge.
US Organic Traffic
−9.6%
89.8M → 81.2M (Ahrefs)
Organic Traffic Value
+4.0%
$8.81B → $9.16B (Ahrefs)
Net Revenue (Yelp IR)
Record 2025
2026 guide: $1.46B–$1.48B
That divergence is fully decoupled monetization. Here's how Yelp got there:
- OpenAI distribution deal. Yelp's verified business data is now part of how OpenAI's products answer "where should I eat in [city]" or "find a [service] near me" queries. Yelp gets paid as a data supplier — not as a website with display ads.
- $270M acquisition of RepairPal (April 2024). RepairPal is the auto-repair vertical. Yelp now owns the structured-data supply for two service marketplaces.
- Yelp Assistant (Yelp's own chatbot for finding local services). Conversion surface that captures intent the AIO surface can't.
- Zocdoc partnership. Yelp powers the underlying business directory for healthcare bookings. More distribution, more licensing.
What Yelp figured out — and what no other directory in this dataset has fully figured out yet — is that AI products need verified, structured, trustworthy supply. The companies building AI assistants don't want to crawl the open web for this kind of data, because the open web is full of unverified business listings, broken phone numbers, and competitor spam. They want to license clean, current, structured data from someone who already does the work of verifying it.
If you are that someone, you get paid. If you are competing against Yelp's listings on the user-attention side, you don't.
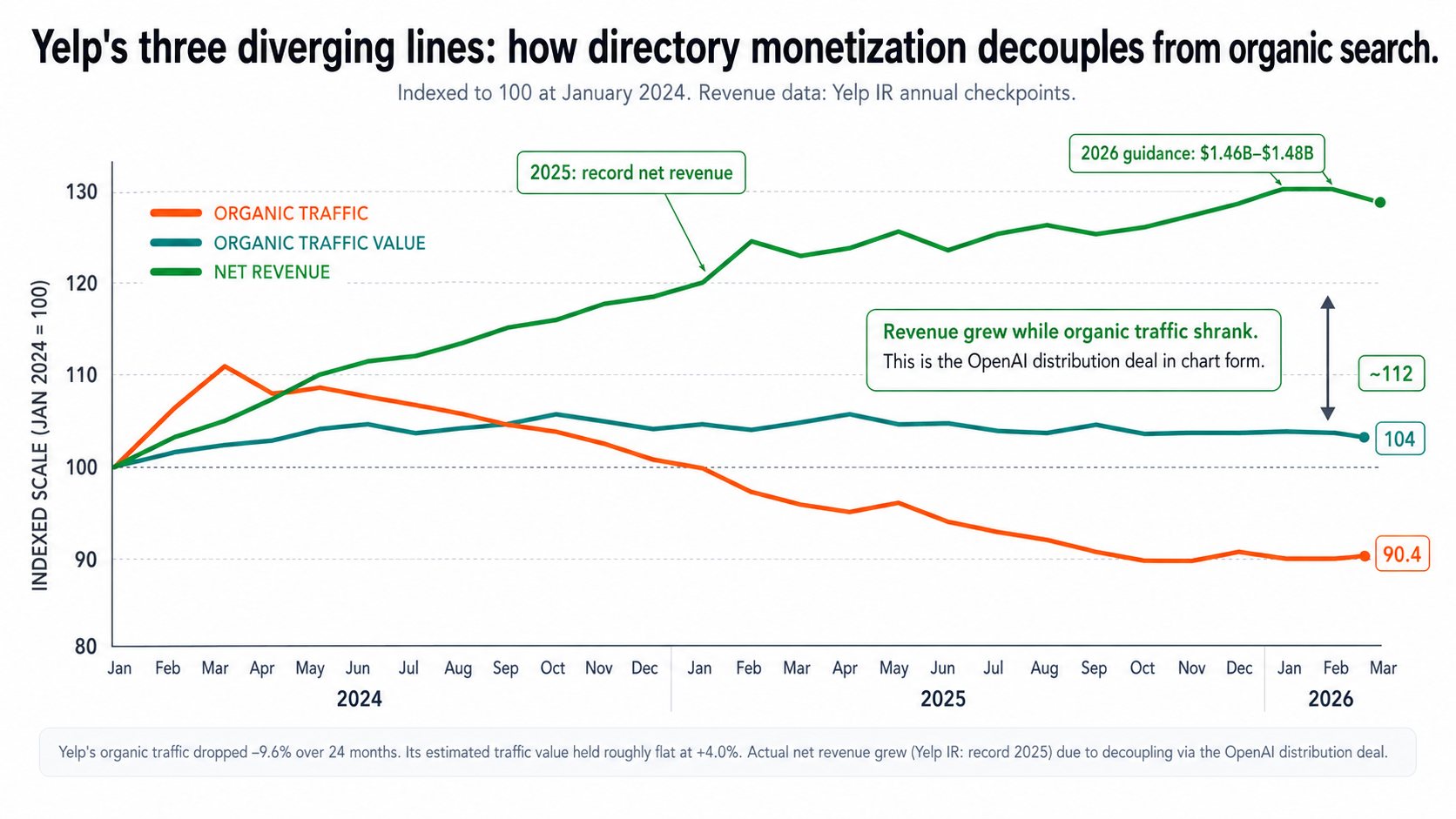 Yelp's organic traffic dropped −9.6%. Its estimated traffic value held flat at +4%. Its actual net revenue grew (Yelp IR: record 2025, 2026 guidance $1.46B–$1.48B). Decoupling, in three lines.
Yelp's organic traffic dropped −9.6%. Its estimated traffic value held flat at +4%. Its actual net revenue grew (Yelp IR: record 2025, 2026 guidance $1.46B–$1.48B). Decoupling, in three lines.
Becoming a supplier — architecture decisions
If you want the option to do what Yelp did in your vertical, the architectural decisions have to start now. Here's the minimum-viable supplier checklist:
- Public, read-only API. Your data has to be available behind an authless (or simply rate-limited) endpoint that LLMs and AI products can crawl predictably.
/api/v1/[entity]/[id]returning JSON. If your data is locked behind login walls, no AI product will license you. DatasetJSON-LD on every data-bearing page. This is the schema.org type that signals to crawlers and LLMs that the page is a structured dataset, not just an article. Most directory sites I look at emitLocalBusinessorArticleschema; almost none emitDataset. Add it.- Freshness SLAs with timestamps. Every record on your site should have a
dateModifiedfield that's truthful. Stale data is worse than no data for AI consumption. - Audit trail. When a record changes, you should be able to say what changed and when. This is what data licensees need to trust your supply.
This is a 2027+ revenue play, not a 2026 one. But the architecture decisions are 2026 decisions. If you wait until your traffic is gone to start thinking about API supply, you've waited too long.
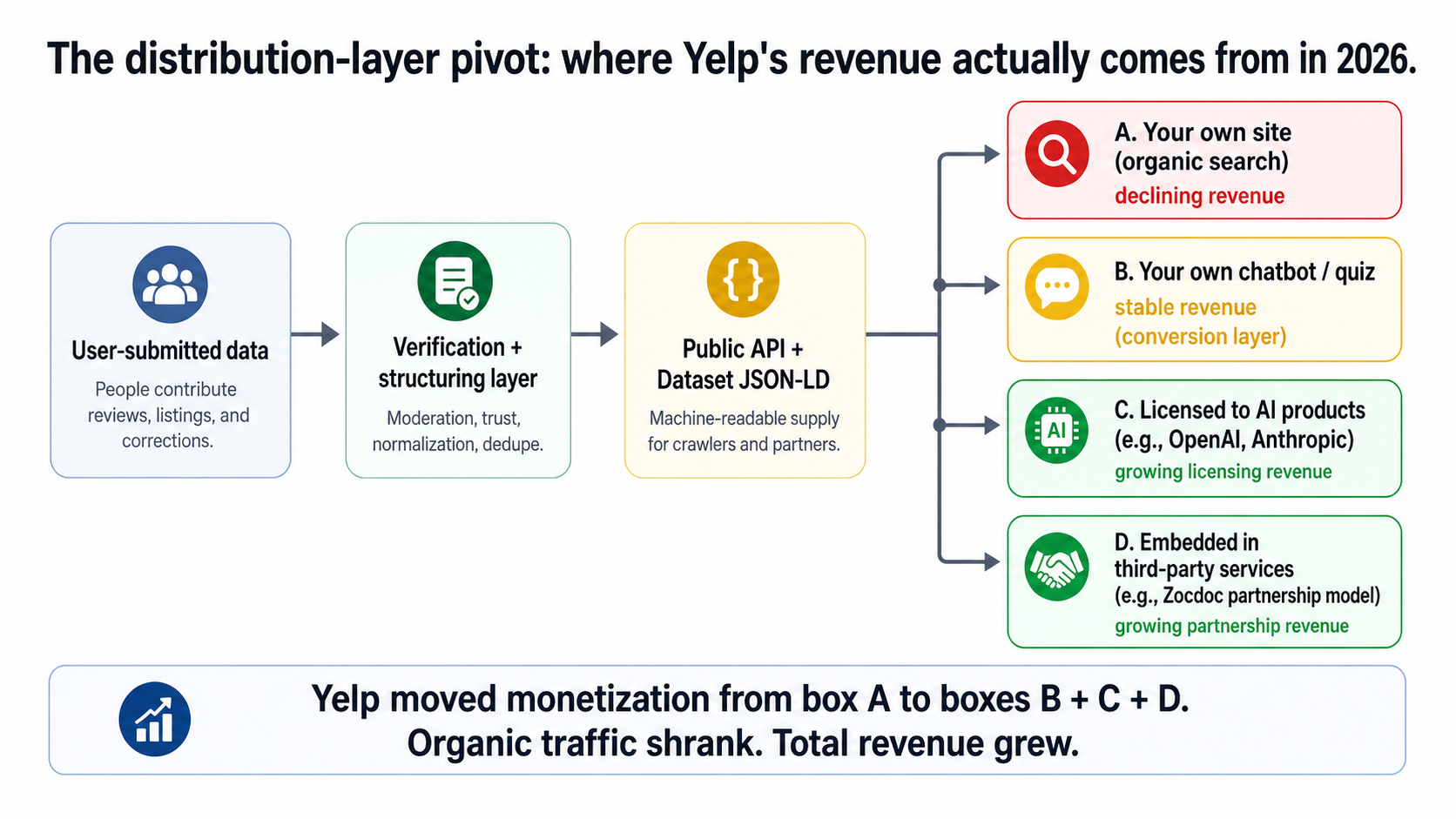 The architecture Yelp pivoted to. Organic traffic is one of four monetization channels — and not the largest one anymore.
The architecture Yelp pivoted to. Organic traffic is one of four monetization channels — and not the largest one anymore.
Get the directory survival audit (PDF)
A printable version of the 5-question audit, the funnel-top 2x2, and the data-moat tier diagram — plus quarterly refreshes of this dataset as the trajectories evolve. Free with your DirectoryGems newsletter signup.
Subscribe to Get the Audit
The decision matrix for directory operators
Six lessons collapse into a five-question audit. Run it on your own directory in the next thirty minutes:
- Is your top-of-funnel query transactional and tied to live or personalized data? (Like Zillow's listings.) — Y / N
- Do you have a first-party data flywheel? Real users contributing real data that the model can't synthesize. — Y / N
- Are you structured for citation?
DatasetJSON-LD, public API, freshness timestamps, audit trail. — Y / N - Do you have presence on the platforms LLMs cite? Reddit, Wikipedia, vertical-specific community sites. — Y / N
- Is your monetization diversified? More than one of: lead-gen, paid product, licensing/distribution, services. — Y / N
Map your score:
- 5/5 yes — You're Zillow. Defend the funnel top, don't get complacent. The Dec 2025 core update is not the last update.
- 3-4/5 yes — You're somewhere between Niche and Yelp. Pick the missing pieces and ship them.
- 1-2/5 yes — You're NerdWallet pre-trough. Recovery is possible but it requires product/funnel restructuring, not just SEO patches.
- 0/5 yes — You're on the bestplaces trajectory. The next core update will accelerate it.
 The 5-question audit. Run it on your directory and your top three competitors. Save this image — it's the whole article in one frame.
The 5-question audit. Run it on your directory and your top three competitors. Save this image — it's the whole article in one frame.
A note on honesty: half-credit answers don't count. "We have an API that requires a paid account" is not a public API. "We have user reviews but they're 5 years old" is not a first-party data flywheel. The audit only catches the patterns if you're honest about where you actually are.
Case study: tapwaterdata.com — running the audit on my own site
I run a few directory sites. The honest one to talk about here is TapWaterData.com — the database of US municipal water systems I run — because it's structurally identical to bestplaces.net, the dataset's worst-performing site, down 86.6%. It has city-by-city pages, contaminant detail pages, EPA data, and (currently) display ads + Amazon affiliate links as the primary monetization. By every dimension of the audit above, it scored 0/5 in early 2026.
Rather than wait to confirm the trajectory, I'm running four pillars in parallel over a 12-week window. Each has a hard validation gate. Two of these will probably fail. That's the point of running them in parallel.
Pillar A — Lead-gen channels beyond Amazon
Switch primary monetization on the highest-traffic city pages from Amazon affiliate to direct lead-gen affiliates: water-testing kits, softeners, RO installs, PFAS class-action retainers.
Validation gate (Week 6): Lead-gen RPM > Amazon RPM on the same page set. If not, the funnel-top intent was wrong.
Pillar B — Paid product portfolio
Three products A/B-tested simultaneously: a $14.99 pre-purchase water-quality report, a $3.99/mo EPA-violation alert subscription, and a free quiz that funnels into Pillar A.
Validation gate (Day 60): Combined RPM (revenue + signups) > $50/1000 on test pages. If not, double down on Pillar A.
Pillar C — Crowdsourced reports
A graduated 3-step rollout: Tally form on top-10 city pages, then a real submission system at /report/submit, then OCR for uploaded test PDFs.
Validation gate: aggregate-view pages ("23 home tests in [zip]") rank in their own right and pull backlinks.
Pillar D — Listicle templates
Best filters by category, contaminant, scenario, brand-vs-brand. Annual refresh in URL. ItemList JSON-LD. Ship one template family, measure for two weeks, then ship the next.
Validation gate (per family): rank check at +14 days. National Today is the cautionary tale for mass-generation.
The cross-cutting infrastructure that enables all four pillars: a public read-only API at /api/v1/, Dataset JSON-LD on every data-bearing page, a single email list seeded from forms across all four pillars, and a quiet but consistent presence on five subreddits.
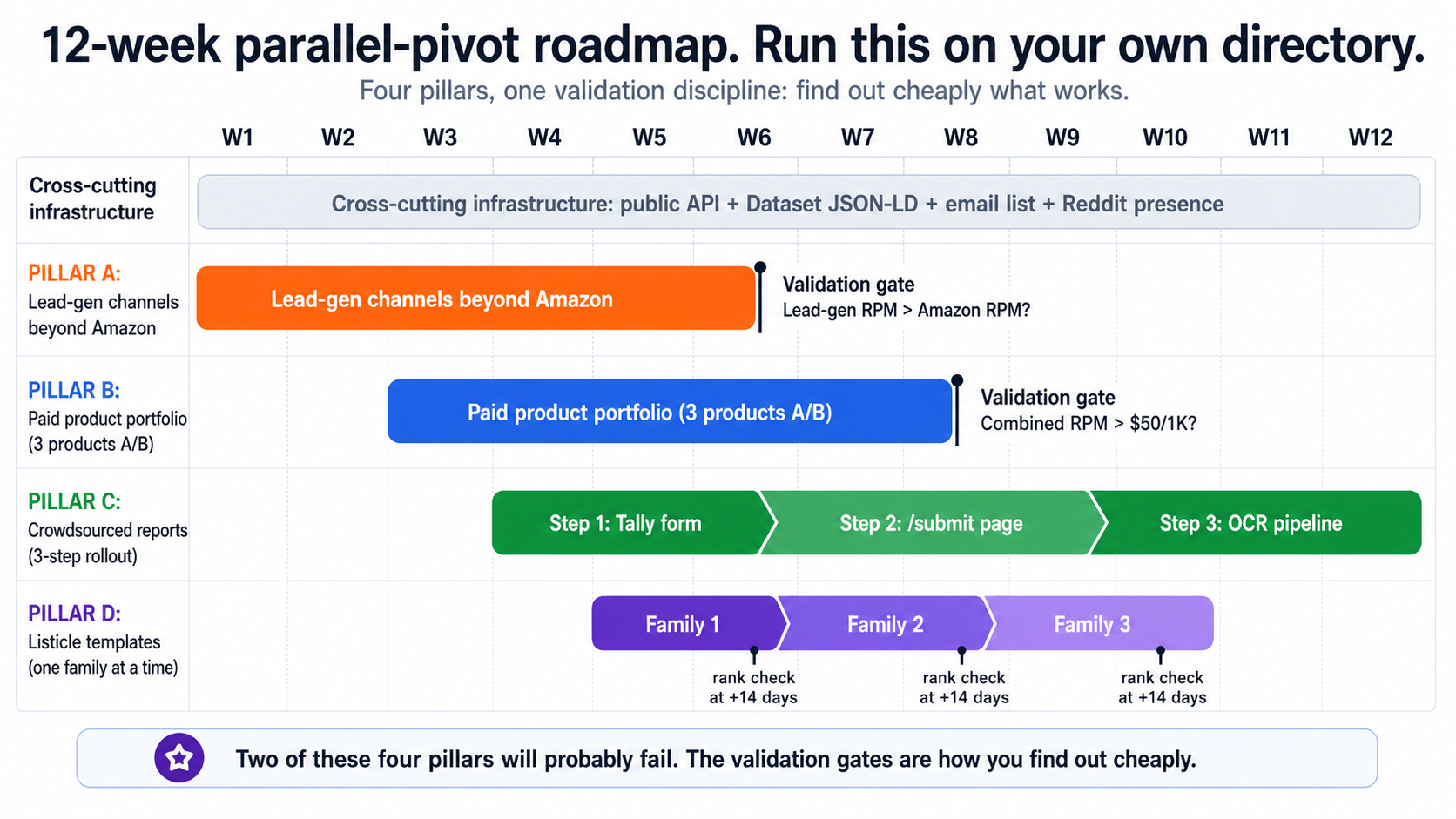 The four pillars I'm running on tapwaterdata.com over 12 weeks. Two of them will probably fail. Each gate is how I find out cheaply.
The four pillars I'm running on tapwaterdata.com over 12 weeks. Two of them will probably fail. Each gate is how I find out cheaply.
I'll publish quarterly updates with the actual numbers — what worked, what failed, what I changed. If you want to follow along, subscribe below and you'll get the next update when it ships.
Follow the four-pillar experiment
I'll publish the actual Week 6, Day 60, and 12-week numbers from TapWaterData — including the two pillars that fail. Get each update in your inbox the day it ships.
Subscribe for Quarterly Updates
What this analysis does not claim
A few things this analysis intentionally doesn't claim, because the data doesn't support them:
- It does not say all directories are doomed. Three patterns are working. They are repeatable.
- It does not say AIO is the only cause. The Dec 2025 core update is layered on top of AIO; some of the declines (Healthline, WebMD) probably owe more to YMYL recalibration than to AIO substitution.
- It does not say recovery is impossible. NerdWallet rebounded 16% from its January 2026 trough in two months. Recovery happens — slowly, partially, and only after a product/funnel restructuring.
- It does not say "Yelp won". Yelp's organic search is shrinking. They built a different machine to make money. That's a strategic pivot, not a search win.
- It does not say programmatic SEO is dead. Niche.com is programmatic SEO. It's holding. The question is what the programmatic pages are, not whether they exist.
Methodology and appendix
All traffic numbers in this article are from the Ahrefs API v3 Site Explorer metrics-history endpoint, pulled on 2026-04-26. Parameters used: country=us, volume_mode=monthly, protocol=both, mode=subdomains, history_grouping=monthly. The mode=subdomains parameter is essential — mode=domain returns near-zero values for every site I checked, an artifact of how Ahrefs joins root and subdomain data.
Comparisons use April 2024 as the pre-AIO baseline (AIO rolled out broadly in May 2024) and March 2026 as the endpoint. April 2026 was rejected as the endpoint because mid-month pulls show roughly half of full-month traffic — that artifact would have inflated every "recovery" claim.
Ahrefs values are estimates of US organic search traffic and traffic value. They are reliable for relative comparison across domains and months. They are not ground-truth GA-confirmed sessions, and you should not read any single number as exact. The patterns hold up under that caveat; the precision of any given percentage doesn't.
Raw data downloads
Three files contain everything that backs this article:
directory-traffic.json— full structured data, meta block + per-domain snapshots + 28-month monthly history per domain. Use for programmatic charting or interactive embeds.directory-traffic-summary.csv— one row per domain, with all baseline / YoY / 24-month deltas. Drop into Datawrapper / Flourish / Excel.directory-traffic-monthly.csv— long format, one row per (domain, month). Perfect for line charts and small-multiples.
If you want to re-run the pull yourself (recommended quarterly):
export AHREFS_KEY="<your-key>"
mkdir -p /tmp/ahrefs-validate
for d in bestplaces.net city-data.com niche.com nerdwallet.com healthline.com tripadvisor.com zillow.com allrecipes.com yelp.com chegg.com webmd.com; do
curl -sS -H "Authorization: Bearer $AHREFS_KEY" \
"https://api.ahrefs.com/v3/site-explorer/metrics-history?target=$d&country=us&volume_mode=monthly&date_from=2024-01-01&date_to=$(date +%Y-%m-01)&protocol=both&mode=subdomains&history_grouping=monthly" \
-o "/tmp/ahrefs-validate/$d-history.json" &
done
waitNote when re-pulling: the current month is always partial. Anchor your endpoint comparisons on the last completed month, not the in-progress one.
Sources referenced but not Ahrefs-validated
To be transparent about which numbers came from which source:
- Wikipedia −8% pageviews — TechCrunch, October 2025. Not pulled via Ahrefs (Wikipedia's organic traffic structure is unique).
- Reddit AIO citations +450% — Digital Bloom 2025 citation analysis. Citation count, not traffic.
- Yelp 2025 record net revenue + 2026 guidance — Yelp Q4 2025 investor relations.
- Yelp / OpenAI distribution deal, RepairPal acquisition, Zocdoc partnership — public business reporting (Yelp IR, CNBC, trade press).
- National Today AI penalty case — Glenn Gabe public writing on the case.
- Per-vertical lead economics ($20–60 water testing, $50–150 softener install, etc.) — operator-side affiliate program documentation, not third-party survey data.
If you cite this article and want primary sources for these claims, the references above are where to start. If a number isn't on this list, it came from the Ahrefs pull.
Final note
I will refresh this analysis quarterly and republish with updated numbers. The patterns are unlikely to flip — Zillow won't suddenly collapse, bestplaces won't suddenly recover. But the magnitudes will shift, NerdWallet's recovery trajectory will resolve one way or another, and at least one of the four pillars on TapWaterData will produce a real data point about whether the strategies in this article actually work for a structurally bad-shaped directory site.
If your directory is in this dataset, get the audit done this week. If your directory isn't, run the audit on it anyway. And if you want to compare notes — subscribe to the DirectoryGems newsletter, reply to any issue, or find me on the platforms my audit told me to be on.
For more directory teardowns and revenue patterns, browse the full case study library.
Related Case Studies

I described what I wanted and Claude Code built an 8,800-line AI sales agent in one session. 665 prospects, 60% open rate, $27/week. Here's the full breakdown.

How Basecamp's founders turned their expertise in remote work into the largest remote job board—from the company that wrote the book on working remotely.
How two developers who met on Twitter turned a $1,000 investment into the world's largest beer discovery platform—working nights and weekends for five years before going full-time.
A family-owned website in Minnesota has quietly become the internet's largest tractor database—475,000 monthly visitors searching for specs on everything from vintage John Deeres to modern Kubotas.